By John Ivan Diaz
A simple Large Language Model (LLM)-powered chatbot that helps users find information about companies. It uses the People Data Labs 2019 Global Company Dataset from Kaggle, the SentenceTransformers All-MiniLM-L6-v2 embedding model, and the Meta Llama 3.2 1B Instruct LLM from Hugging Face. While the chatbot is simple and retrieves only a small fraction of the dataset, its goal is to demonstrate LangChain, ChromaDB, and Retrieval-Augmented Generation (RAG) for LLM orchestration, vector storage, and retrieval.
Discovery Phase
Use Case Definition
Natural Language Processing (NLP) enables computers to understand the semantic meaning of text. Traditional NLP uses techniques like rule-based methods and statistical models, which, although useful, often compromise flexibility and accuracy. Advancements in Large Language Models (LLMs) have enabled more natural and context-aware understanding through Deep Learning and Transformers.
This project aims to create a simple chatbot that helps users find information about companies using Large Language Models. It accepts questions from users, retrieves context from a dataset containing company information, and responds with answers grounded in the retrieved information. The goal is to keep the chatbot simple while demonstrating the use of frameworks such as LangChain, ChromaDB, and Retrieval-Augmented Generation (RAG).
Data Exploration
The project used the People Data Labs 2019 Global Company Dataset from Kaggle. It comprises over 7 million CSV records from companies, including domain, year founded, industry, size range, locality, country, LinkedIn URL, and current number of employees.
Sample row data:
name: IBM
domain: ibm.com
year founded: 1911
industry: Information Technology and Services
size range: 10001+
locality: New York, New York, United States
country: United States
linkedin url: linkedin.com/company/ibm
current employee estimate: 274,047
total employee estimate: 716,906
For a lightweight demonstration, the project retrieved only 100,000 rows of data.
Architecture and Algorithm Selection
The project used the SentenceTransformers All-MiniLM-L6-v2 embedding model and the Meta Llama 3.2 1B Instruct LLM from Hugging Face.
Development Phase
Data Pipeline Creation
Dataset Ingestion
The dataset is preprocessed using a text splitter to break long text into smaller chunks. Each chunk of text is tokenized, normalized, and converted into embeddings using the Embedding Model. The embeddings are stored in ChromaDB.
Inference
The user types a question in the Gradio GUI. This input text is tokenized, normalized, and converted into embeddings using the same embedding model. These embeddings are compared with the stored dataset embeddings in ChromaDB using Retrieval-Augmented Generation to retrieve the most relevant texts. The retrieved texts are passed to the large language model to generate a natural language response. This response is displayed back to the user in the Gradio GUI.
Text splitting, embedding calls, and ChromaDB integration are handled using the LangChain framework.
Evaluation
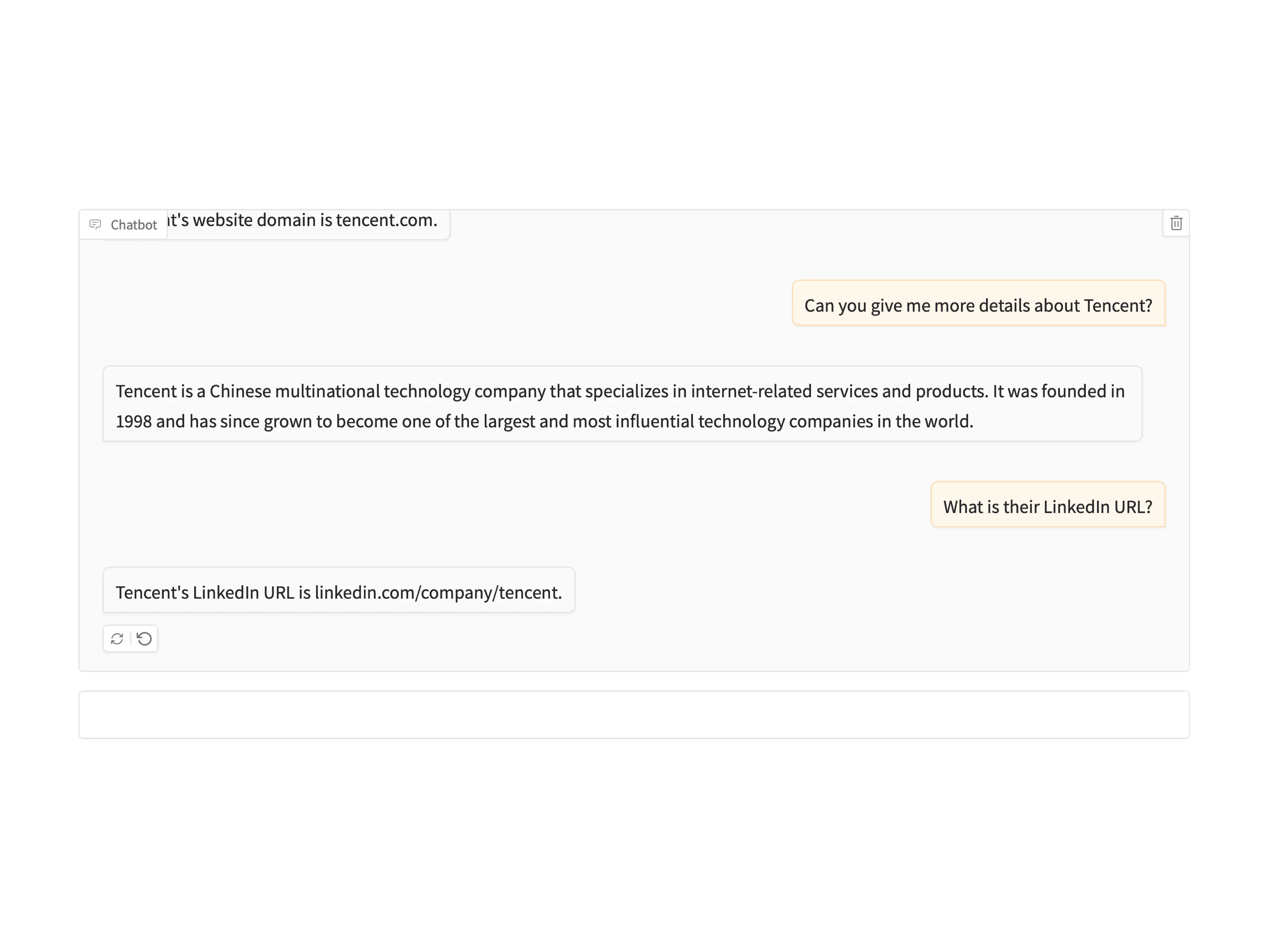
Sample Prompts and Responses
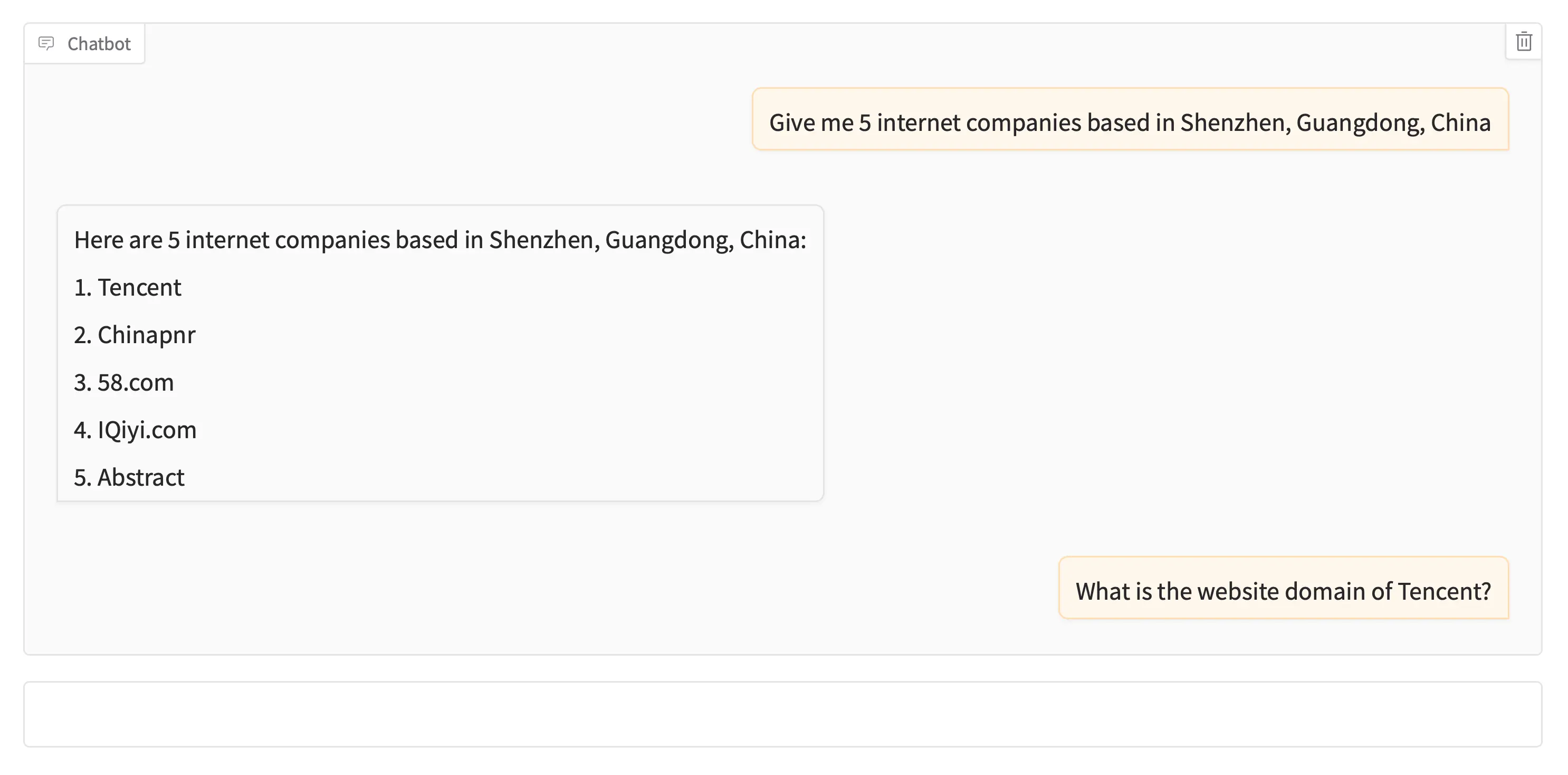
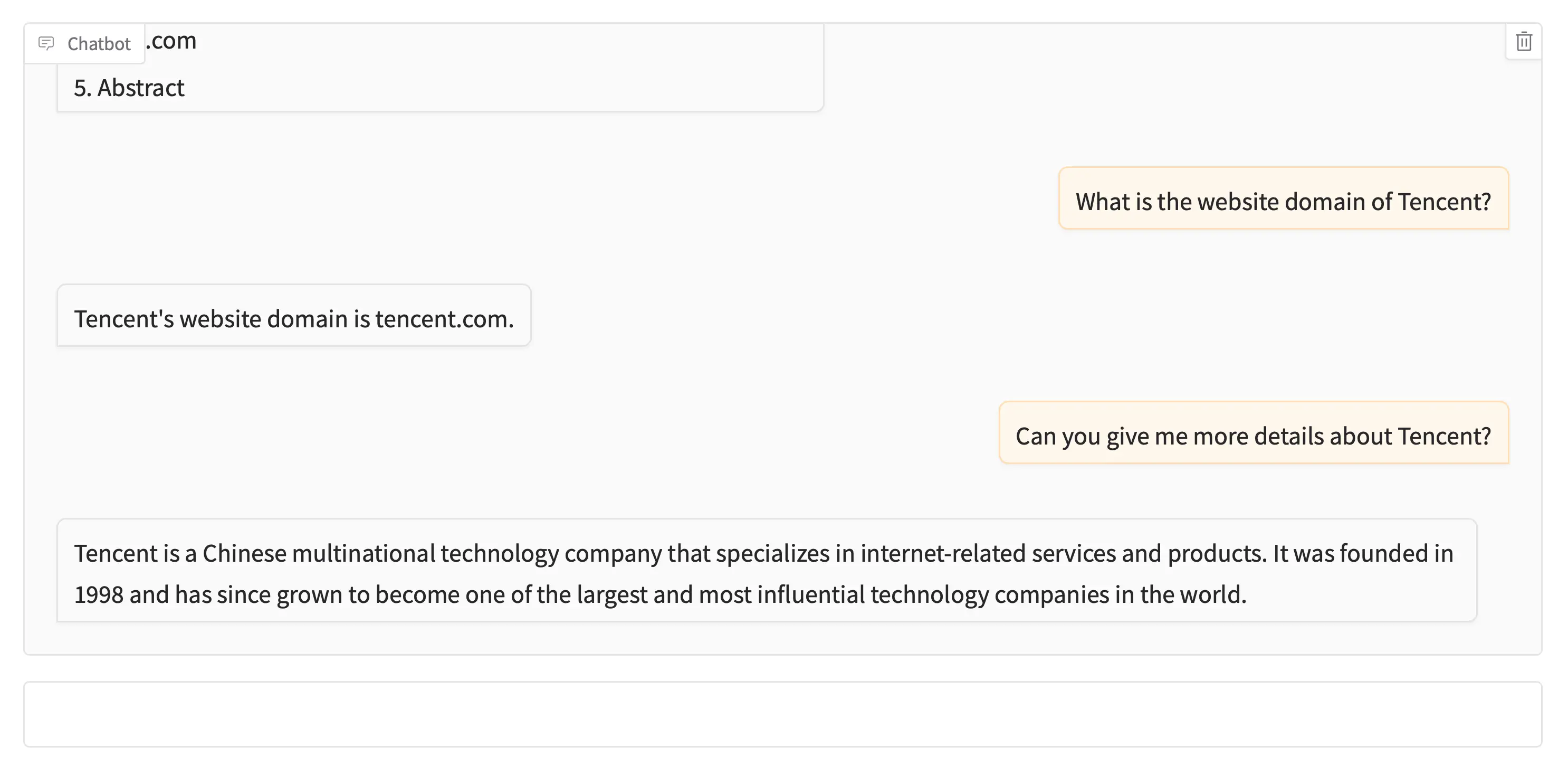
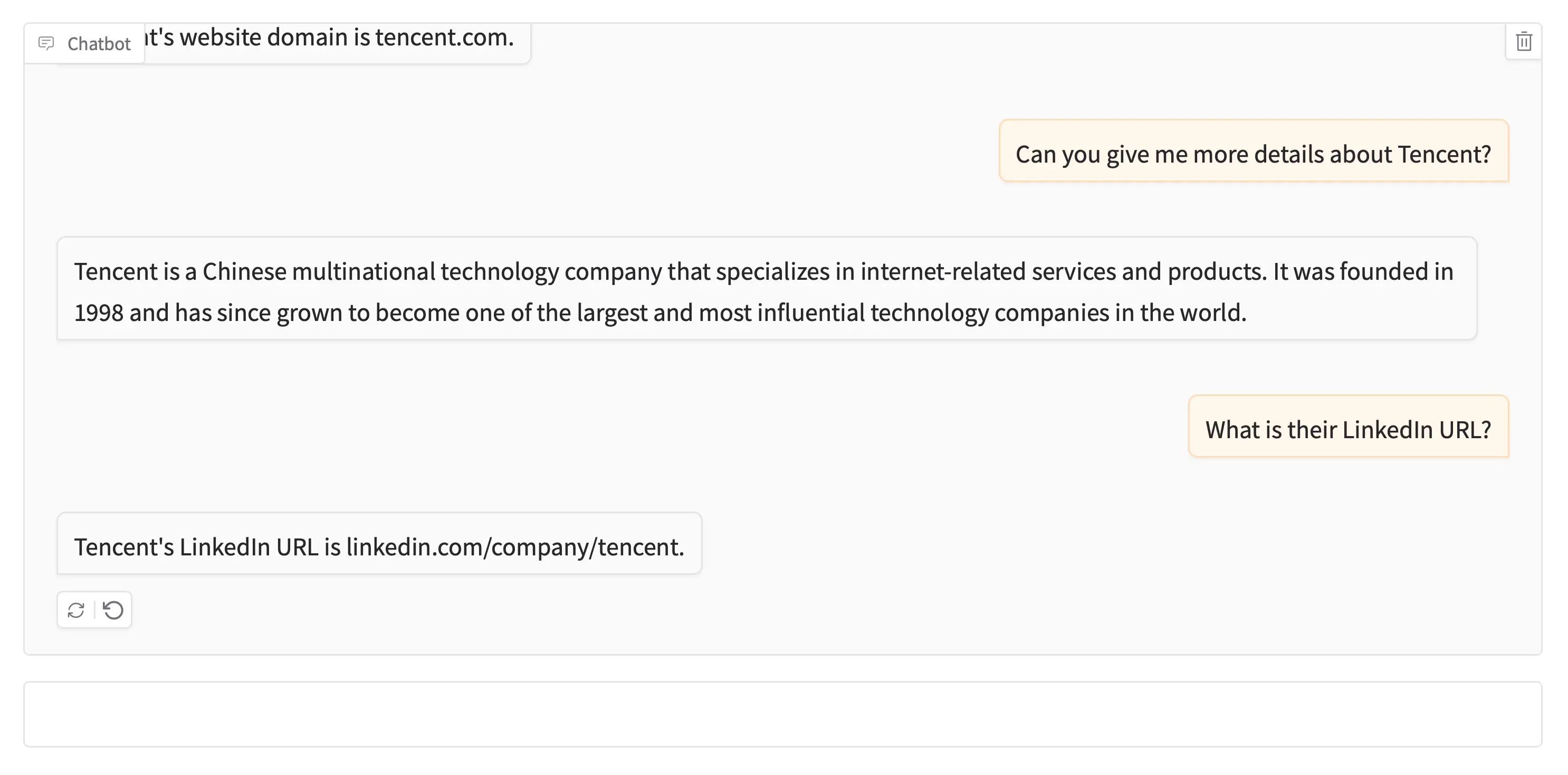
Groud Truth
Tencent based in Shenzhen, Guangdong, China:
name: Tencent
domain: tencent.com
year founded: 1998
industry: Internet
size range: 10001+
locality: Shenzhen, Guangdong, China
country: China
linkedin url: linkedin.com/company/tencent
current employee estimate: 37,574
total employee estimate: 42,617
Presentation of Results
Guide for Local Testing
- Download the dataset from Kaggle
- Create a folder named "data" and place the dataset in it
- Clone the repository from GitHub
- Create a virtual environment
python -m venv venv
- Activate the virtual environment
source venv/bin/activate
- Install dependencies
pip install -r requirements.txt
- Create a .env file and place your HuggingFace Access Token in it
HUGGINGFACEHUB_API_TOKEN=hf...
Note: The project uses meta-llama/Llama-3.2-1B. Make sure to have access from repo authors.
- Ingest the dataset
python ingest-database.py
- Run inference
python chatbot.py